
Y el verbo se hizo carne (y se traduce a proteínas)
Ya tenemos un texto escrito en ARN. Un texto de cuatro letras constituidas por los cuatro nucleótidos adenina, citosina, guanina y uracilo. Ya hemos visto, que incluso en un texto lineal como lo es una molécula de ARN puede existir dopplergangers: secuencias invertidas, especulares, complementarias... La unidimensionalidad esconde estructuras de dos dimensiones... esas estructuras van a dar una molécula tridimensional, y esa molécula, por medio de la selección natural irá cambiando en el tiempo, es decir, va a reflejar la cuarta dimensión en su composición.
El estudio de significados ocultos en los textos del Pentateuco, que en la tradición hebrea forman la Torá, núcleo de la religión judía (Génesis, Éxodo, Levítico, Números y Deuteronomio, tuvo su origen en la España de los siglos XII y XIII, especialmente en las juderías de Guadalajara y Zaragoza. La lectura cabalística artificial utiliza tres mecanismos analíticos básicos: Gematría, Notaricón, Temurá. Cada letra del alfabeto hebreo, como elemento creador tiene asignado un número, lo que confiere significados crípticos a la Torá.
Si un texto alfabético admite ese grado de complejidad, pensemos en ese mundo de ribozimas replicándose en el barro, evolucionando... alcanzando niveles altísimos de sofisticación. De repente, esa información escrita en cuatro letras da un salto cuando una máquina, el ribosoma, del que hablaré más adelante, les permite traducir la información del ARN a un código químicamente más versátil: las proteínas basadas en cadenas de aminoácidos. De repente, el verbo, las ribozimas, se hacen carne.

Para convertir, traducir, toda la información que acumula el ARN necesitamos un código para traducir esa información a un nuevo código. Por ese motivo, vamos a ver
¿Qué es el código genético?
Para explicar el código genético voy a utilizar otro código muy utilizado como analogía: el código máquina de nuestros computadores. La información digital se guarda en ceros y unos, los famosos bits, es decir un código binario: O es apagado y 1 es encendido, por que se trata de un soporte electrónico electrónico. La información biológica se guarda en cuatro "bases nitrogenadas" basadas en química de carbono: adenina; uracilo; citosina y guanina. La unidad de información informática es el octeto, conocido como byte, es decir, una combinación de ocho elementos, ceros y unos. La unidad biológica es el triplete, es decir, combinaciones de tres bases nitrogenadas. Si hacéis un poco de cálculo os daréis cuenta que un byte tiene 256 combinaciones posibles (2x2x2x2x2x2x2x2 = 256). Es decir, que 256 octetos nos sirven para tener el alfabeto latino, todos los signos de puntuación e incluso comandos. Cuando en 1963 los informáticos eligieron este código lo pensaron de la siguiente manera: con dos dígitos puedo representar 22 caracteres, es decir 4 caracteres, con tres dígitos 23 caracteres. Para 120 caracteres, 27 =128. Al final se decidieron por un código basado en 8 dígitos ya que 28 = 256 y así podían representar las letras del alfabeto latino, el griego, minúsculas y mayúsculas, los números y distintos comandos... se olvidaron de asignar un byte de 8 dígito para nuestra letra Ñ. De esta manera, el código binario de apagados y encendidos podía codificar todos los símbolos que necesitamos. En el caso del ARN lo que la selección natural benefició fue...
Un código degenerado
El código genético tiene 64 combinaciones posibles (4x4x4 = 64). El código genético codifica para 20 aminoácidos que son los elementos con los que se construyen las proteínas, las proteínas son cadenas de aminoácidos. Además el código tiene un triplete para comenzar la lectura y tres tripletes para finalizar la lectura. El código tiene cuatro letras: A, G, C y U, que se agrupan de tres de en tres. Esto da lugar a 64 combinaciones diferentes (4x4x4). Sin embargo sólo hay 20 aminoácidos diferentes que están en las proteínas. Del código genético se dice que es "degenerado" porque varios codones sirven para especificar un mismo aminoácido.
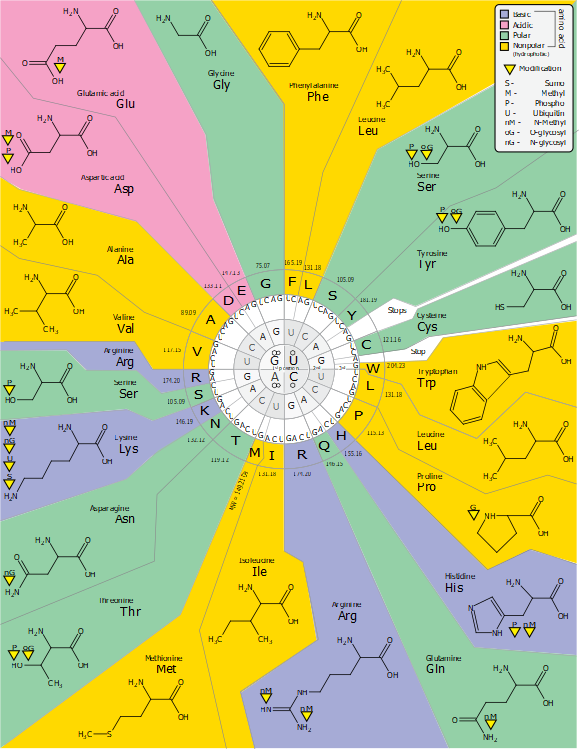
Gracias a este código, los ribozimas pudieron traducir su información basada en 4 nucleótidos a un código de 20 aminoácidos. ¿Qué ventaja tienen los aminoácidos frente a los nucleótidos? bien, primero hay aminoácidos de tamaño pequeño y de tamaño grande. Los hay ácidos, básicos, hidrofílicos de carga neutra e hidrofílicos. Por lo tanto el código es ahora más versátil.
Cada tres bases del ARNm especifican un aminoácido
Un triplete o codón es una secuencia de tres nucleótidos del ARNm, secuencia que determina la formación de un aminoácido específico. Teniendo en cuenta que existen cuatro ribonucleótidos diferentes (U, C, A y G), hay 64 tripletes distintos.
Un mismo aminoácido puede ser codificado por diferentes tripletes
Existen 64 tripletes distintos y hay solamente 20 aminoácidos diferentes, por lo que codones diferentes determinan el mismo aminoácido. A esto se le llama degeneración del código genético. Los codones que especifican el mismo aminoácido se denominan sinónimos.
Como consecuencia de la degeneración del código genético, muchas mutaciones en la tercera base de un codón son fenotípicamente silentes, es decir, el codón mutado especifica el mismo aminoácido que el codón normal.
Los tripletes no se solapan
Cada codón es una secuencia de ribonucleótidos, y no comparte ninguno de ellos con los codones adyacentes en la cadena de ARNm. Por ejemplo: La secuencia 5´AUGCCGUAUGUGUUUUAA 3´ sería 5´AUG CCG UAU GUG UUU UAA 3´
La lectura del código es continua, sin interrupciones
Cualquier pérdida o ganancia de un sólo ribonucleótido produce a partir de ese punto un cambio en todos los aminoácidos desde el lugar de la alteración. El código genético actual ha podido evolucionar desde otros códigos mas simples, pero en éstos códigos los nucleótidos también tuvieron que leerse de tres en tres, ya que, de no ser así, el cambio en la pauta de lectura habría "destruido" la información genética que se había ido acumulando.

La evolución del código informático es tan similar que debemos recordarlo. Los pioneros de la computación escribían su código en código máquina, esto es, en ceros y unos. La forma que tenían para escribir este código en un soporte que pudiese ser leído por las computadoras eran las tarjetas perforadas.

Para un humano, escribir en ceros y unos no es intuitivo, por lo que pronto, los informáticos desarrollaron los lenguajes ensambladores como un intento de sustituir el código de ceros y unos en un código basado en comandos escritos en palabras usando nuestro alfabeto.
Como un computador puede interpretar y ejecutar sólo el código máquina basado en ceros (apagado del procesador) y unos (encendido), existen programas especiales, denominados traductores, que traducen programas escritos en un lenguaje de programación al lenguaje máquina de la computadora. En el caso del código genético, el código "máquina" basado en secuencias de ARN, con su código de adenina, citosina, guanina y uracilo, se traduce a proteínas basadas en los 20 aminoácidos mediante un traductor llamado ribosoma.
Video 3: mRNA Translation (Advanced). Fuente: DNA Learning Center
El código es aplicable a todos los organismos de la tierra
Esto significa que un triplete determinado producirá siempre el mismo aminoácido, en cualquier organismo. Esto es así por que todos los seres vivos del planeta, y me refiero a virus, bacterias, protozoos, hongos, vegetales y animales procedemos de un único antepasado. Una estructura de ARN con capacidad de traducir su información a un código de aminoácidos. Esta estructura surgió por evolución y tuvo tanto éxito que todos somos sus descendientes. Todos los seres vivos estamos emparentados. Por ese motivo, un gen humano puede ser leído en una bacteria, o un virus puede hacer que su ARN sea leído en una célula humana. Esto es la base de la ingeniería genética.
Hay una excepción a esta universalidad: el código genético mitocondrial es diferente en algunos organismos, de manera que los aminoácidos determinados por el mismo triplete o codón son diferentes en el núcleo y en la mitocondria.
¿Por que esa estructura de ARN que podía traducir a su código es nuestro antepasado?
Por que tuvo éxito al desarrollar una cubierta proteica que le hizo poder salir del barro para conquistar todo el planeta. Todos los seres vivos procedemos del mismo ribozima, el que desarrolló el ribosoma que le permitió sintetizar proteínas con las que protegerse y abandonar la seguridad de las capas del barro húmedo.
A los ribozimas que vivían entre las capas de las arcillas y podían traducir su código de ARN a un código de aminoácidos gracias a una máquina molecular llamada ribosoma se les llama protovirus: virus ARN con cubierta proteica y ribosoma.

Y es en esta sopa biológica donde los protovirus vivían felices haciendo lo que más nos gusta a los seres vivos: reproducirnos, demostrarle al mundo que nuestro relato si merece la pena y que tenemos que producir muchas copias, más copias que nuestros vecinos y prevalecer en la cuarta dimensión que es la del tiempo. Pero, como todas las situaciones felices siempre viene alguien a estropear la fiesta.
¿Cómo surge un supervirus por recombinación de dos virus?
La tragedia para los protovirus ya se venía mascando desde hacía tiempo. En ese paraíso que era un planeta con océanos y ríos ricos en moléculas orgánicas los protovirus solo debían de replicarse. Esto planteaba un problema: para dividir su ARN los protovirus debían desemsamblar su cubierta proteica y copiar su ARN, luego, los ribosomas traducían parte de su información para hacer las proteínas de la cápside que se autoensamblaban porque estaban hechas de aminoácidos complementarios, en forma y en cargas eléctricas.
Esto planteaba un problema: su ARN estaba desnudo, rodeado de otros ARNs desnudos... y claro, tanta desnudez llevaba a cierta concupiscencia genética. El resultado: protovirus recombinantes, es decir, producto del entrecruzamiento genético entre protovirus similares. Esto que aquí cuento es algo que todavía existe y ocurre. ¿Acaso no habéis leído que el SARS-CoV-2 que ha causado la pandemia del Covid-19 es un supervirus que surgió por la recombinación entre un virus humano y virus de murciélago? El mecanismo por el que aparecen supervirus es muy similar a lo que ocurría cuando no había células y los protovirus vivían replicándose en la sopa biológica.
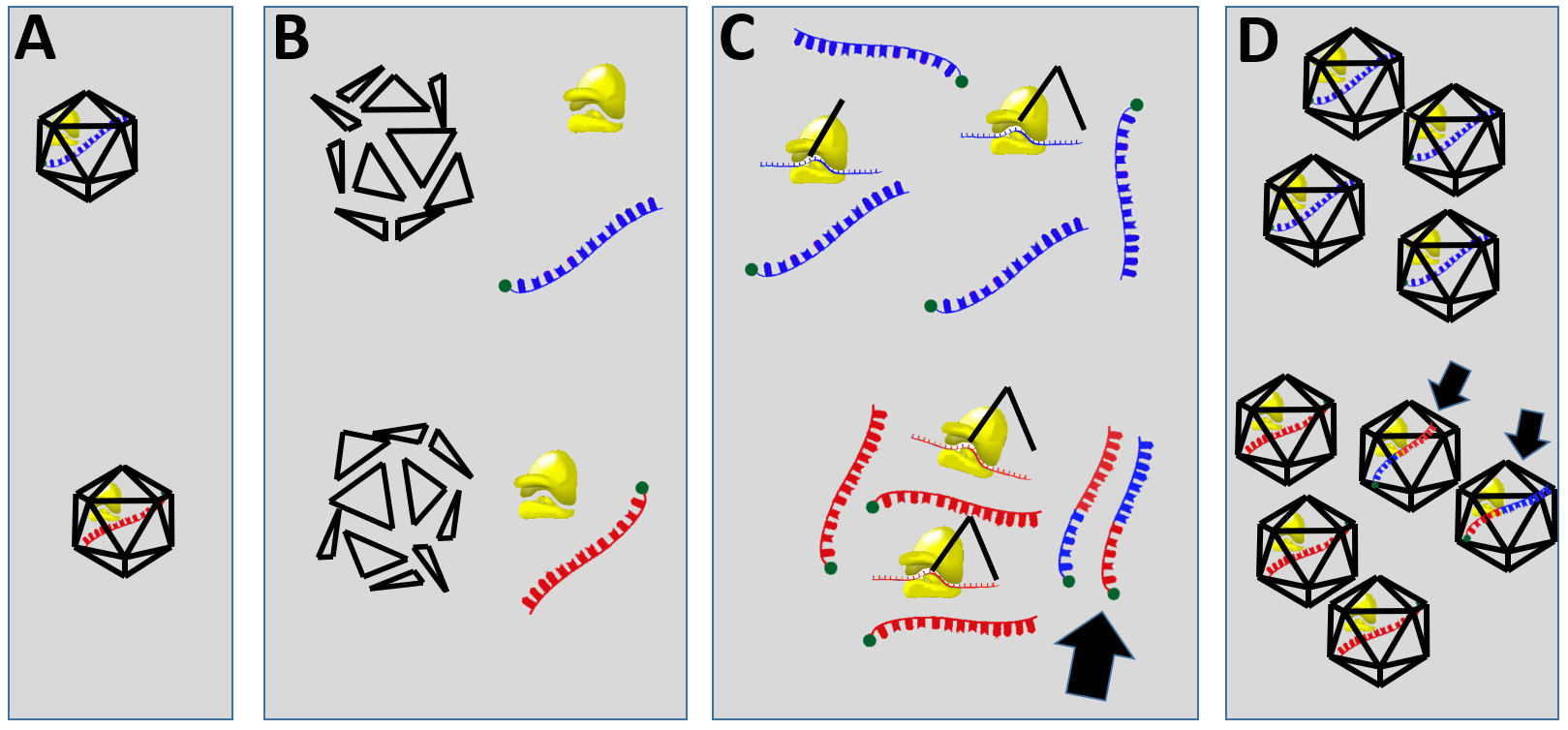
El problema de que encapsides ARN de otro virus que no sea el tuyo te hace un poco ser un virus cachón. Y eso es un problema, en las novelas venezolanas y también en el mundo de los protovirus. Normalmente los virus cachudos o recombinantes suelen ser supervirus responsables de pandemias.
Otro de los problemas que tenían estos virus de ARN era que el ARN es un buen soporte de información, pero de repente aparición un soporte mejor: el ADN. El ADN es similar al ARN de doble cadena solo que su azúcar está menos oxidado, y como sabemos el oxígeno es muy reactivo, por lo tanto, que la molécula soporte de la información esté menos oxidada la hace más resistente. Esto era bueno para virus muy grandes que ya tenían una información valiosa que merecía conservar y que no sufriese tantas mutaciones. Además, una de las bases, la timina, sustituía al uracilo del ARN. La timina es similar al uracilo solo que es un poco más grande ya que tiene un grupo metilo extra. Esto hace que la molécula de ADN sea más rígida que el ARN y por tanto más compacta y menos expuesta a rupturas.
En los tiempos en los que solo había ribozimas y protovirus, éstos ya fueron capaces de desarrollar protovirus de ARN y protovirus ADN. Ahora, la información genética tenía un soporte que era capaz de resistir de manera más eficaz a las mutaciones. Esto permitía que los protovirus de ADN fuesen cada vez más ricos en información.
Y en esto que aparecieron los primeros organismos biológicos basados no en una cubierta proteica, sino en una envoltura grasa: la membrana formada por una bicapa lipídica. En ese momento, la vida se dividió en dos clasificaciones: Acytotas constituídos por los protovirus y Cytota formado por las nuevas estructuras con bicapa lipídica que serían similares a las arqueobacterias actuales. El prefijo "Arqueo-" significa "antiguo, arcaico, primitivo" y procede del griego "archaio"

¿Qué ventaja tiene una membrana plasmática frente a una cápside proteica? Dos grandes ventajas, por un lado son capaces de almacenar los nutrientes que antes estaban libres y dos en las células con membrana plasmática el ADN nunca está fuera de la célula y por tanto es difícil que su ADN sufra recombinaciones indeseadas y que "Luis Alfredo" sea hijo de quien tiene que ser y no del lechero.
Cuando apareció las primeras células, las arqueobacterias, con una membrana lipídica que les permitía duplicar su material genético dentro de una barrera, su membrana, todo cambió. Las bacterias primitivas comenzaron a crecer masivamente. La mayoría de las sustancias orgánicas que conformaban la sopa biológica pasaron al interior del citoplasma de las nuevas entidades biológicas.
Los protovirus estaban quedando sin su hábitat natural ¿A dónde se iban los nutrientes? bien, los nutrientes estaban siendo secuestrados en el interior de las arqueobacterias, así que los virus que fueron capaces de entrar en el interior de las arqueobacterias se encontraron con la sopa biológica que se les estaba robando. Y comenzaron a entrar y salir de las arqueobacterias. Entraban para poder dividirse en la sopa biología del citoplasma bacteriano, salían para buscar nuevas arqueobacterias. En esto apareció un protovirus mutante, un protovirus que carecía de los genes que codificaban para los ribosomas, por tanto, se dividían más rápido. ¿Es esto importante? lo vamos a ver

Solución: Virus A 30 minutos virus B 20 minutos. En 6 horas tendremos de A 4096 virus, y de B tendremos 262144. Si en vez de horas hablásemos de miles de años podemos entender porqué los virus actuales carecen de ribosomas.
Como vemos en el problema 2, en biología, el que se reproduce mantiene su discurso genético, su información hereditaria en la cuarta dimensión. Los que no se reproducen son flor de un día y desaparecen de la línea de tiempo.
No hay comentarios:
Publicar un comentario
Cada vez que lees un artículo y no dejas un comentario, alguien mata a un gatito en alguna parte del mundo...